Large Language Models: Instead of Searching, Just Ask


Hello everyone, long time no see. 👋
I've been thinking about the implications of Large Language Models (LLMs) and thought I'd share some of my early thinking behind it. What started as a few notes in Apple Notes rapidly grew to a long dump of shower thoughts, links, articles and papers. This is my best shot at structuring it all.
I've now bucketed my thoughts into what should roughly amount to 6 separate articles:
1. Instead of searching, just ask
- Part 1: Philosophical implications of LLMs becoming more pervasive in society
- Part 2: Are Large Language Models furthering our loss of agency?
- Part 3: Indexing, monetizing, navigating - Rethinking the foundations of the interwebs
2. Creativity, inspiration, plagiarism - The intellectual property belly dance
3. Abstracting knowledge
- Part 1: What direction are we taking?
- Part 2: What's to come?
This is the first article of the series.
"Instead of searching, just ask"
I found the title for this article 3 weeks ago when the team over at Slite shared their new product launch for Ask. Ask is a cool tool, they're essentially helping you to search your internal knowledge base by asking questions. Other smart people are working on the topic but one very simple thing stuck to mind after seeing their Product Hunt launch:
Don't ask me why or how but when reading this, something clicked and for an instant I sat like this:

I had the sudden realisation that I'd never put much thought into the difference of meaning between "searching" and "asking". When you think about it, searching is active, asking is passive. Asking is an activity that allows us to receive knowledge from an external source. On the other hand, searching is seen as a way to gain knowledge independently. It involves actively researching and exploring various sources of information in order to come to an understanding and a personal opinion. This can involve reading, watching videos, listening to lectures, and any other activity that involves gathering information.
How searching and asking changed over time
90s nostalgia in 3-2-1
Let's take a quick trip down memory lane to remind ourselves how search came about in the early days. One of the first documented search efforts was pioneered by Alan Emtage in 1990. The McGill student made the first interface enabling the search of files scattered on FTP servers around the web and created a search bar where users could, with a regular expression, look for FTP files. With Archie, you weren't seeing contents, you were seeing links to indexed FTP servers.

This changed with the rise of web crawlers built specifically to crawl the web for content. In 1993, Jumpstation was one of the first to use webcrawlers. Being able to search for website titles and headings was a huge improvement at the time. With crawlers, the race was on to index as much of the web as possible. Lycos was an early mover in 1994 but got overtaken shortly after by Altavista. Altavista was a pioneer in many respects but most notably for bringing natural language search interfaces to the mainstream.
What did AskJeeves do differently?
This is where our bald character at the top of the articlecomes into play. The younger folks in the audience may not recall him but it's Jeeves, the butler character from AskJeeves.com launched in 1996.
Instead of showing you links as answers, AskJeeves would directly look for similar questions in its database and the quality of the results were striking back then. It was both unique in it's question-answering format but also served as a meta-search layer offering results from a range of competitors to best answer the question of the user.
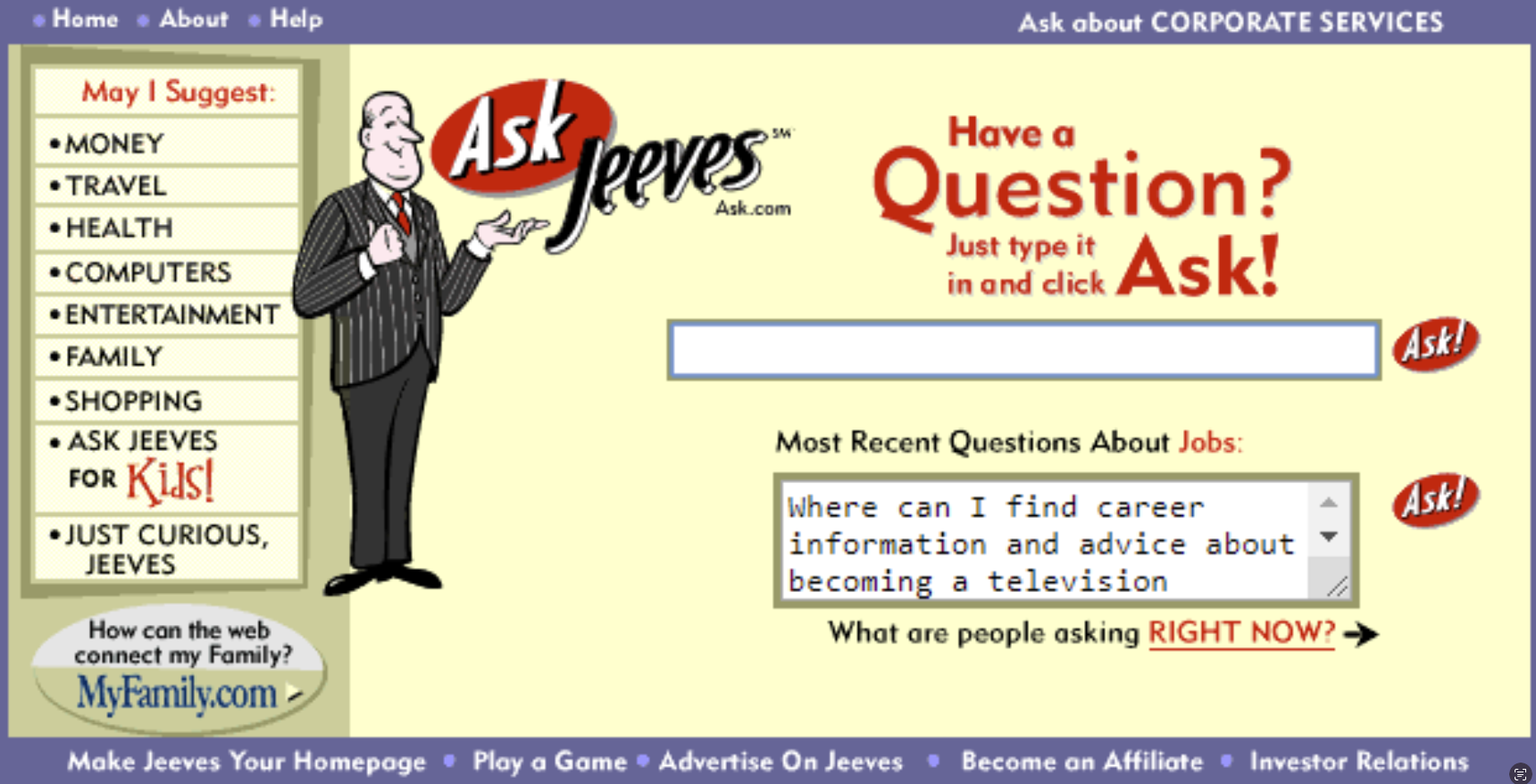
AskJeeves (which in the mean time had rebranded Ask.com) became known as one of the first functional attempts at using natural language to answer questions. I believe that if good old Jeeves was still around, he'd be pretty excited about the use of Large Language Models for search.
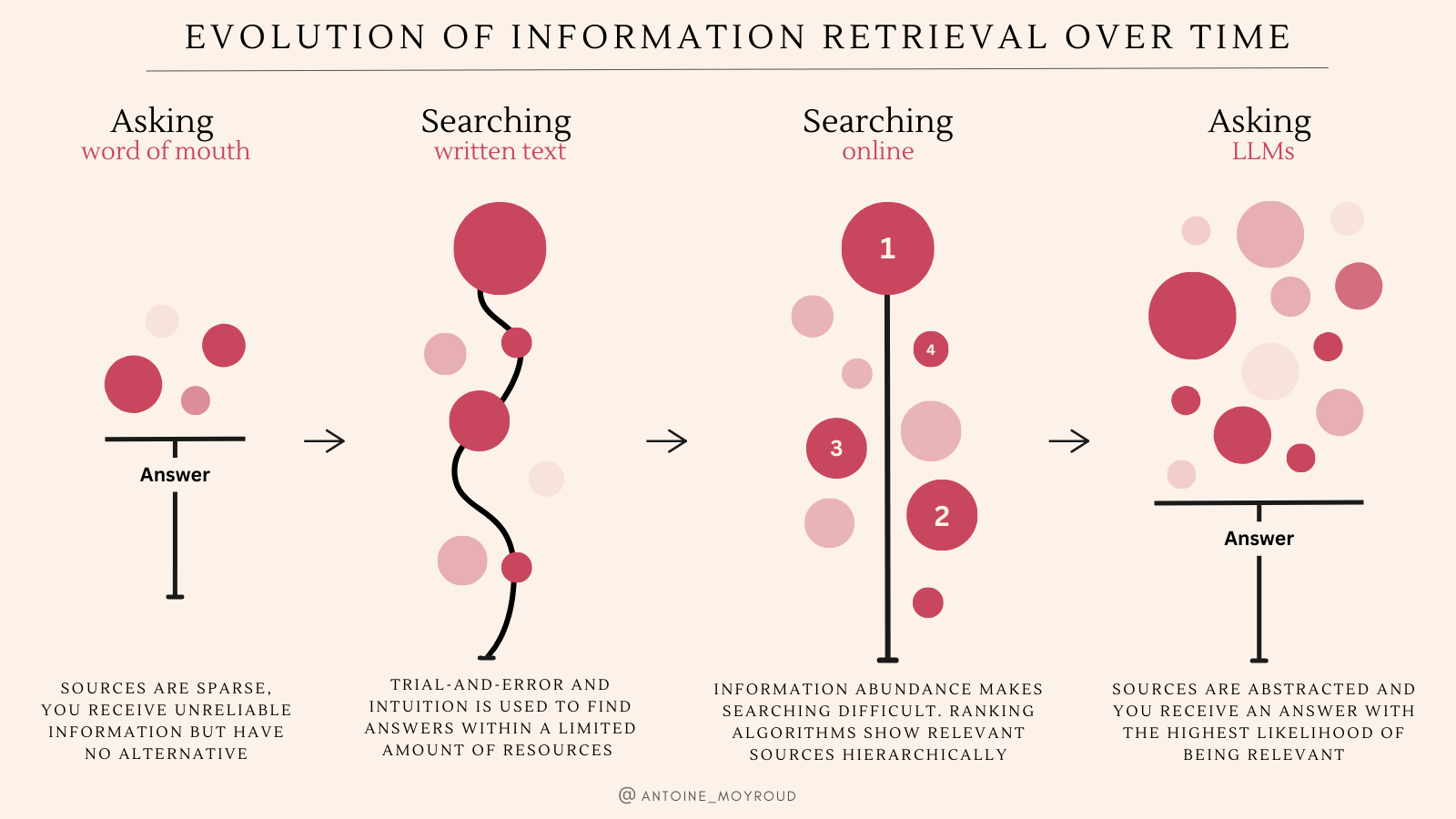
If we believe in a world where information will mainly be accessed by asking questions. Then the next question becomes:
How do we ask effectively?
Research in Prompt Engineering and Chain of Thought are at the forefront of this and stem from two key insights:
- Fine-tuning the way a question is asked can yield a significant uplift in performance. Companies specialising on this single task have emerged to help people save time in learning how to best interface with Generative AI (Promptbase and Prompthero come to mind)
- Combined with prompting techniques such as Chain of Thought (CoT), large language models can solve complex reasoning problems. This technique uses multi-step reasoning and decomposes complex problems into separate easier steps that it can solve in isolation. By "chaining" the answers together it becomes able to solve much more complex problems. Here is an example from the reference research paper on the topic:
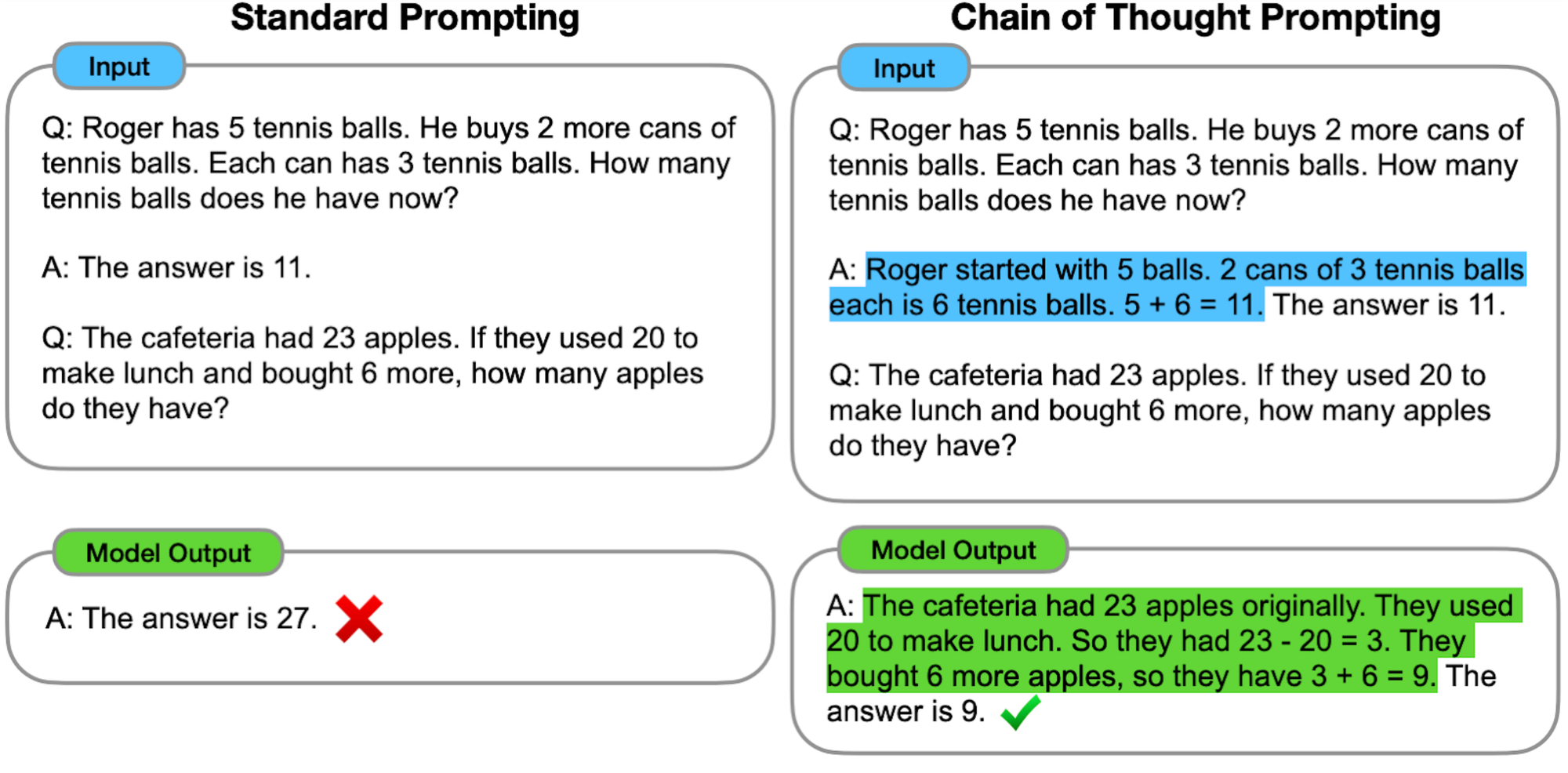
One of the thoughts I haven't been able to properly pin down and tie to this topic is the duality between:
- the sudden floodgates of information being opened for the average person
- the fact that the most qualified people will extract the most value (knowledge of prompting, chain of thought)
All I have for now is a meme that highlights part of this thinking but if you have thoughts on the topic, do share!

Building trust
Once you've understood how to interact with an LLM, how can you make sure that the information it provides is trustworthy? We'll address this in a future post but LLMs are notorious for their ability to convincingly share factually wrong information also known as "hallucinations" (side note, I prefer the term "confabulation" from the medical world where brain-damaged patients fill in gaps of memory by fabrication). If we aren't able to separate fact and fiction, are we losing agency as humans?
Are Large Language Models furthering our loss of agency?
If you view LLMs as the next iteration of "search" enabling the rise of conversational AI as the standard medium for search, the topic of "loss of agency" is one that comes up quickly.
By looking at the evolution of information retrieval over the past 100 years, an interesting pattern emerges: should conversational AI interfaces become the new norm for search, we would effectively be reverting to the town hall equivalent of getting information by word of mouth but at internet scale. Back in the 1920s, the only information was the newspaper and the library. You had few sources to search from for information, the radio was only getting started with the BBC and French Radio. If you wanted to learn something, you'd walk to a library where a highly qualified person specialised in information retrieval would help narrow down your ask and recommend reliable books to read. The internet totally blew up the scale of information retrieval. Any random person with an internet connection could suddenly access millions of results, without the librarian to help you filter the noise...
I found a fascinating excerpt on this topic dating back to the year 2000. H.Stephen Wright, a librarian at Northern Illinois University discussed the impact of search engines and the perception of truth:
I find this observation all the more relevant 23 years later. Questioning the perception of understanding is thought-provoking. Does it matter that the truth is actually the truth when the information shared to you is projected as such? If users believe that the information source is trust-worthy, they will assume that the information itself is factual ("It's relayed by the BBC, it must be true" vs "It's relayed by Infowars, it must be wrong")...
Next week, we'll continue to dig into the loss of agency that automation and LLMs contribute to. I'll discuss the blurred lines of curation and distribution and how the two have evolved with the rise of new forms of information sharing.
If you're curious about LLMs and their impact on society, consider subscribing as I've got a bunch of articles in the pipeline on the topic. If you aren't yet curious about LLMs, well, that's only a matter of time. I cover other topics around tech & entrepreneurship in the meantime. My past post was on the topic of User Research and how I think it'll become mainstream.
Don't hesitate to share your thoughts with me, I'm very open to discussing the topic, even more so if you disagree with points I've made!



