Garry Tan, LOC-maxxing and code abundance


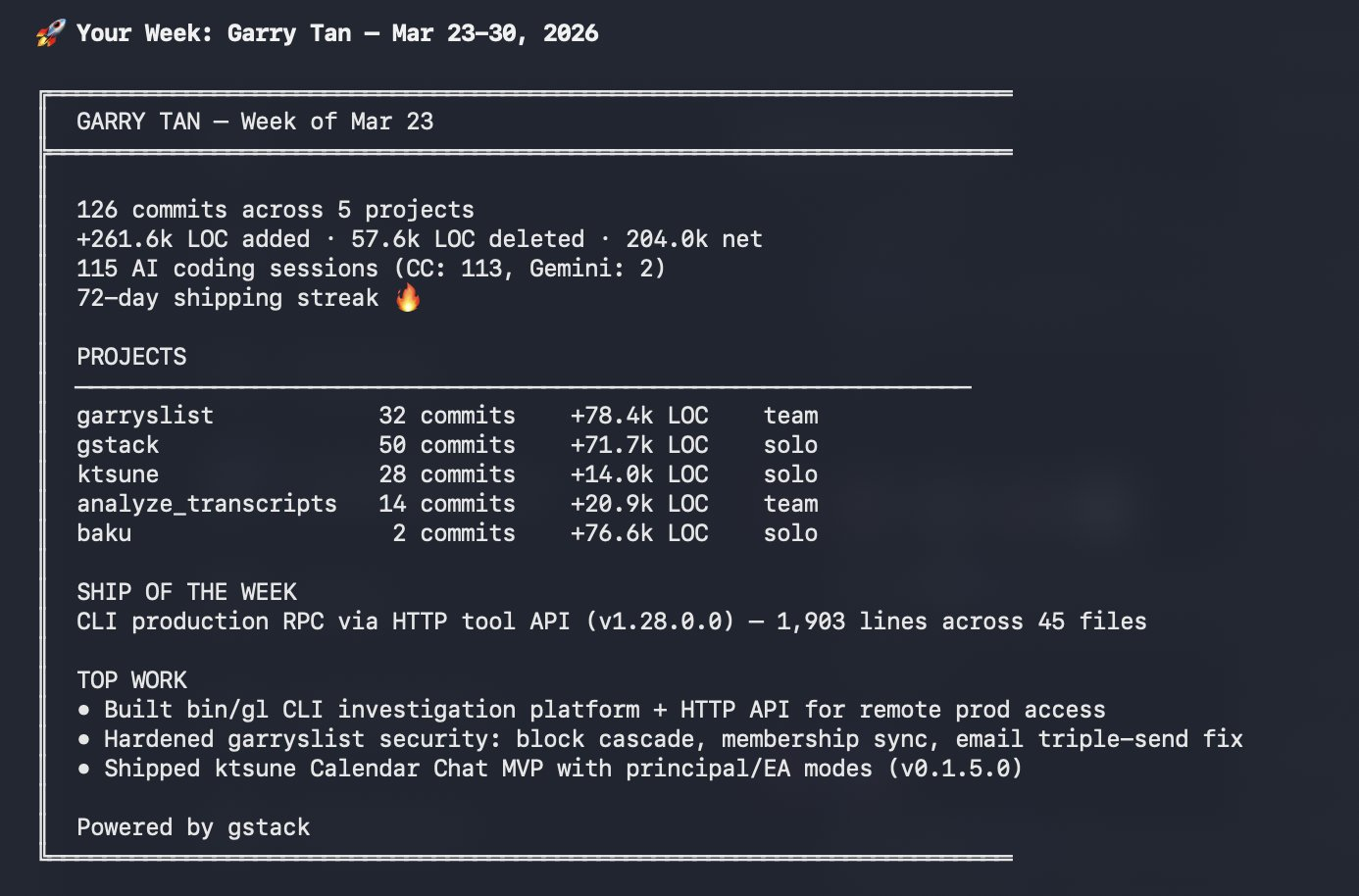
Y Combinator CEO Garry Tan open-sourced gstack, his Claude AI-powered "virtual dev team" highlighting the 10s of thousands of lines of code (LOC) that have been generated. He argues that in the agentic AI era, high LOC output is now a strong signal of speed and productivity, not a flaw. He's been on a full LOC rampage ever since, calling the old "LOC is bad" belief a dying sacred cow because his agents just execute reliably while he directs them.
The LOC debate is mixing together separate questions:
- Are lines of code a useful proxy for intelligence or engineering quality?
- Does code volume and structure matter less if agents are going to write and review most of the code anyway?
- Why is Garry making LOC the talk of the town in the LLM era?
My view is simple: LOC is still the wrong metric.
1. LOC was never a serious proxy for intelligence
Lines of code are easy to count. The problem is that LOC was never the right number to look at. LOC is not a measure of intelligence, it's a measure of volume, and volume is too ambiguous to tell you much on its own.
- More code: can mean stronger tests, better documentation, explicit handling of edge cases, or clearer logic. It can also mean duplication, bad abstractions, unnecessary boilerplate, or generated slop.
- Less code: can mean elegant, functional code. It can also mean dense cleverness that becomes painful to read and understand when you haven't written it.
2. Why LOC is being pushed as a metric
What changed in the LLM era is that people seem to be mapping code volume to token consumption. The implicit assumption follows something like this:
It seems to be used as a close analog to frontier-level thinking. That is where the logic breaks for me. Tokens measure compute spent. Lines of code measure output volume. Neither tells you whether the compute was spent on the right abstraction, the right fix, or the right part of the problem.
3. LOC-maxxing only makes sense if you think slop is basically free
I would like to offer the LOC-maxxing term to this conversation.

The people most tempted by the "LOC narrative" are often the most pro-code-abundance. If you believe models can generate thousands of lines cheaply and agents can curate the mess afterwards, volume starts to feel like intelligence.
That first part I can understand, agents really do make messy codebases less punishing than they used to be. The leap I do not buy is the next one: that cheap generation makes clean code and structure matter less.
4. The cost of bloated codebases is still there
As generation gets cheaper, the burden shifts later in the SDLC. The code shows up faster, but that does not mean it survives curation, review, or production. In an agent-heavy workflow, generated>reviewed>merged>production LOC can diverge massively.
That is where LOC-maxxing breaks down. If you really believe code is abundant, then raw LOC should matter less (not more) as a metric and communicating on LOCs in production doesn't make sense to me as a flex?
This is the part I would genuinely want Garry's view on. How much confidence does he actually have in those lines of code? His "email triple-send fix" is an example that I'd imagine a code review process would flag?
Good structure will not prevent every bug, but it does make it much easier to fix the root cause instead of layering patches onto "broken code". Agents do better when the codebase has enough structure that a change doesn't ripple into five places you didn't expect. You can generate diffs all day sure but you're mostly creating more things to doubt if you don't know what's in there.
Even if I force myself into the most AGI-pilled version of this argument, I still do not see why LOC would become the metric. The strongest version of the claim is not that more lines means more intelligence. It is that each token is being allocated in the most intelligent possible way. And even then, if that is true, then the output could just as easily be shorter and cleaner or it could involve generating many alternatives and keeping only a small retained subset in production.
Either way, the thing being optimized is not lines of code. It is usefulness per token so even in the best possible agentic future, LOC is still a bad shortcut.
The real question is whether the model spent its tokens on the right abstraction, the right fix, and the right amount of exploration.
TLDR
- LOC is not a clean measure of intelligence.
- In the LLM era, it gets even more misleading because people map output volume onto token spend, and token spend onto intelligence.
- In an agentic workflow, a lot of code is just intermediate output that is generated then discarded before it ever becomes trusted change. That means higher LOC often reflects search and exploration, not better engineering.
- Agents do make code easier to generate, navigate, and modify. They do not (yet) make it cheap to trust, and they do not make messy systems healthy when you do not understand your codebase in the first place.



